Using PySpark to demonstrate spark Transformation and actions on RDDs and stages/DAG evaluation-Part3(-How to avoid Shuffle Joins in PySpark)
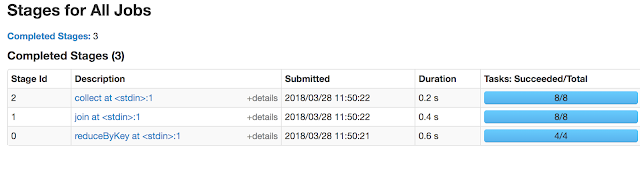
In this part, lets demonstrate the spark transformations and actions on Multiple RDDs using pySpark. Lets consider two datasets as: dataset1=["10.1.0.1,1000","10.1.0.2,2000","10.1.0.3,3000"]*1000 dataset2=["10.1.0.1,hostname1","10.1.0.2,hostname2","10.1.0.3,hostname3"] I wish to get the final o/p as following by aggregating the Bytes on 1st dataset incase of duplicate records. 10.1.0.1,hostname1,100000 Approach-1: 1st aggregate the dataset1 by IP address, save as RDD , next create an RDD from 2nd dataset and apply join on two RDDs. dataset1_rdd=sc.parallelize(dataset1).map(lambda x: x.split(",")).mapValues(lambda x: int(x)).reduceByKey(lambda x, y:x+y) dataset2_rdd=sc.parallelize(dataset2).map(lambda x: tuple(x.split(","))) for i in dataset1_rdd.join(dataset2_rdd).map(lambda x:str(x[0])+","+str(x[1][1])+","+str(x[1][0])).collect(): print i 10.1.0.1,hostname1,1000...