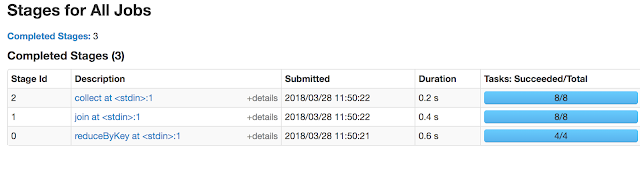
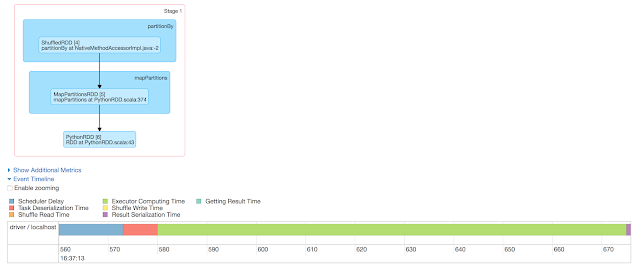
Through the experiment, we will use following connections information: /usr/bin/pyspark logger = sc._jvm.org.apache.log4j logger.LogManager.getLogger("org"). setLevel( logger.Level.INFO ) file: connections.csv srcIp,dstIp,srcPort,dstPort,protocol,bytes 1.1.1.1,10.10.10.10,11111,22,tcp,1000 1.1.1.1,10.10.10.10,22222,69,udp,2000 2.2.2.2,20.20.20.20,33333,21,tcp,3000 2.2.2.2,30.30.30.30,44444,69,udp,4000 3.3.3.3,30.30.30.30,44444,22,tcp,5000 4.4.4.4,40.40.40.40,55555,25,tcp,6000 5.5.5.5,50.50.50.50,66666,161,udp,7000 6.6.6.6,60.60.60.60,77777,162,tcp,8000 Q1. Find the Sum of Bytes sent by each srcIp? headers=sc.textFile("file:///data/connections.csv").first() filtered_rdd = sc.textFile("file:///data/connections.csv").filter(lambda x: x!=headers and x.strip()) //Tranformations -> filter , No of Stages->1 for i in filtered_rdd.map(lambda x: (x.split(",")[0], int(x.split(",")[-1]))).reduceByKey(lambda x...