Tableau integration with sparkSQL and basic data analysis with Tableau
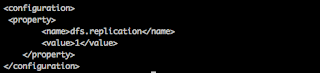
Steps for Tableau integration with sparkSQL and basic data analysis: ================================================ Run the spark-Sql in NameNode[sparkSql server node] as: /opt/spark/sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=10001 Download & install tableau-10 from the site: https://www.tableau.com/products [14-days trail version] Download & install tableau driver for spark-SQL: https://downloads.tableau.com/drivers/mac/TableauDrivers.dmg Open tableau & connect to sparkSQL. Provide server as NameNode IP & port as 10001 [as in step-1 above] Select Type as ‘SparkThriftServer’ Select Authentication as ‘Username and password’ Provide username as ‘hive’ [This is same as in hive-site.xml] Provide password as ‘hive@123’ [This is same as in hive-site.xml] Search & select the database name in ‘Select Schema’ dropdown. [This is the same parquet db sparkJobs created ] ...