Using PySpark to demonstrate spark Transformation and actions on RDDs and stages/DAG evaluation-Part2
In this part, we consider the unstructured texts to demonstrate the spark transformations and action using pySpark.
file:///data/text.csv
rdd=sc.textFile("file:///data/text.csv")
myrdd.take(2)
[u'Think of it for a moment \u2013 1 Qunitillion = 1 Million Billion! Can you imagine how many drives / CDs / Blue-ray DVDs would be required to store them? It is difficult to imagine this scale of data generation even as a data science professional. While this pace of data generation is very exciting, it has created entirely new set of challenges and has forced us to find new ways to handle Big Huge data effectively.', u'']
myrdd.map(lambda x: x.lower().split()).take(2)
[[u'think', u'of', u'it', u'for', u'a', u'moment', u'\u2013', u'1', u'qunitillion', u'=', u'1', u'million', u'billion!', u'can', u'you', u'imagine', u'how', u'many', u'drives', u'/', u'cds', u'/', u'blue-ray', u'dvds', u'would', u'be', u'required', u'to', u'store', u'them?', u'it', u'is', u'difficult', u'to', u'imagine', u'this', u'scale', u'of', u'data', u'generation', u'even', u'as', u'a', u'data', u'science', u'professional.', u'while', u'this', u'pace', u'of', u'data', u'generation', u'is', u'very', u'exciting,', u'it', u'has', u'created', u'entirely', u'new', u'set', u'of', u'challenges', u'and', u'has', u'forced', u'us', u'to', u'find', u'new', u'ways', u'to', u'handle', u'big', u'huge', u'data', u'effectively.'], []]
myrdd.flatMap(lambda x: x.lower().split()).take(10)
[u'think', u'of', u'it', u'for', u'a', u'moment', u'\u2013', u'1', u'qunitillion', u'=']
sc.textFile("file:///data/text.csv").flatMap(lambda x: x.lower().split()).filter(lambda x: x not in stopwords).take(10)
[u'think', u'moment', u'\u2013', u'1', u'qunitillion', u'=', u'1', u'million', u'billion!', u'can']

file:///data/text.csv
rdd=sc.textFile("file:///data/text.csv")
myrdd.take(2)
[u'Think of it for a moment \u2013 1 Qunitillion = 1 Million Billion! Can you imagine how many drives / CDs / Blue-ray DVDs would be required to store them? It is difficult to imagine this scale of data generation even as a data science professional. While this pace of data generation is very exciting, it has created entirely new set of challenges and has forced us to find new ways to handle Big Huge data effectively.', u'']
Q1: Convert all words in a rdd to lowercase and split the lines of a document using space.
myrdd.map(lambda x: x.lower().split()).take(2)
[[u'think', u'of', u'it', u'for', u'a', u'moment', u'\u2013', u'1', u'qunitillion', u'=', u'1', u'million', u'billion!', u'can', u'you', u'imagine', u'how', u'many', u'drives', u'/', u'cds', u'/', u'blue-ray', u'dvds', u'would', u'be', u'required', u'to', u'store', u'them?', u'it', u'is', u'difficult', u'to', u'imagine', u'this', u'scale', u'of', u'data', u'generation', u'even', u'as', u'a', u'data', u'science', u'professional.', u'while', u'this', u'pace', u'of', u'data', u'generation', u'is', u'very', u'exciting,', u'it', u'has', u'created', u'entirely', u'new', u'set', u'of', u'challenges', u'and', u'has', u'forced', u'us', u'to', u'find', u'new', u'ways', u'to', u'handle', u'big', u'huge', u'data', u'effectively.'], []]
myrdd.flatMap(lambda x: x.lower().split()).take(10)
[u'think', u'of', u'it', u'for', u'a', u'moment', u'\u2013', u'1', u'qunitillion', u'=']
Q2: Next, I want to remove the words, which are not necessary to analyze this text. We call these words as “stop words”; Stop words do not add much value in a text. For example, “is”, “am”, “are” and “the” are few examples of stop words.
sc.textFile("file:///data/text.csv").flatMap(lambda x: x.lower().split()).filter(lambda x: x not in stopwords).take(10)
[u'think', u'moment', u'\u2013', u'1', u'qunitillion', u'=', u'1', u'million', u'billion!', u'can']
Q3. How can i Count the words by first three characters in a word?
stopwords = ['is','am','are','the','for','a','of','it']
[(k,len(v)) for (k,v) in sc.textFile("file:///data/text.csv").flatMap(lambda x: x.lower().split()).filter(lambda x: x not in stopwords).groupBy(lambda x: (x[0:3])).take(100)]
[(u'all', 12), (u'sci', 3), (u'(li', 1), (u'\u2013', 4), (u'sce', 1), (u'rev', 1), (u'sca', 20), (u'sco', 2), (u"'am", 1), (u'occ', 1), (u'ret', 5), (u'(if', 1), (u'it.', 2), (u'alt', 2), (u'que', 6), (u'(il', 1), (u'ima', 6), (u'lit', 1), (u'wea', 2), (u'ver', 8), (u'han', 5), (u'ln', 1), (u'pla', 4), (u'-i', 1), (u'rf', 2), (u'yea', 1), (u'add', 9), (u'jvm', 1), (u'hap', 3), (u'sig', 1), (u'vel', 1), (u'4:', 1), (u'fin', 6), (u'\u201ccl', 1), (u'fil', 19), (u'imm', 2), (u'opt', 6), (u'non', 1), (u'rel', 1), (u'amo', 3), (u'far', 1), (u'+ci', 1), (u'upl', 1), (u'dat', 106), (u'fol', 8), (u'(ha', 2), (u'pop', 1), (u'mom', 2), (u'\u2018la', 2), (u'not', 37), (u'ema', 1), (u'bit', 2), (u'is!', 1), (u'nor', 1), (u'bro', 3), (u'bat', 1), (u'bla', 2), (u'lat', 7), (u'err', 2), (u'tra', 93), (u'fur', 2), (u'dif', 15), (u'tre', 1), (u'try', 1), (u'cas', 5), (u'bad', 1), (u'bil', 1), (u'eff', 7), (u"'pr", 3), (u'did', 2), (u'div', 5), (u'dpk', 1), (u'upd', 1), (u'dir', 4), (u'muc', 9), (u"'gu", 1), (u'art', 10), (u'pan', 3), (u'bef', 2), (u'fit', 3), (u'mas', 1), (u'8:', 1), (u'~/.', 3), (u'sec', 3), (u'us', 10), (u'sou', 14), (u'run', 9), (u'ter', 8), (u'6:', 1), (u'mus', 1), (u'sug', 2), (u'df', 2), (u'fre', 1), (u'suc', 4), (u'sbt', 2), (u'for', 17), (u'blu', 1), (u'alr', 10), (u'rep', 8), (u'goa', 1)]
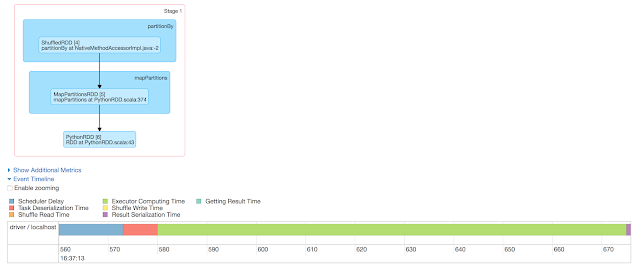
Now, Lets analyse the stages/DAG for the above transformations and actions:
No of stages=2
Breakup for stage-0

BreakUp for stage-1

Comments