Using PySpark to demonstrate spark Transformation and actions on RDDs and stages/DAG evaluation-Part1
Through the experiment, we will use following connections information:
/usr/bin/pyspark
logger = sc._jvm.org.apache.log4j
logger.LogManager.getLogger("org"). setLevel( logger.Level.INFO )
1.1.1.1,10.10.10.10,11111,22,tcp,1000
1.1.1.1,10.10.10.10,22222,69,udp,2000
2.2.2.2,20.20.20.20,33333,21,tcp,3000
2.2.2.2,30.30.30.30,44444,69,udp,4000
3.3.3.3,30.30.30.30,44444,22,tcp,5000
4.4.4.4,40.40.40.40,55555,25,tcp,6000
5.5.5.5,50.50.50.50,66666,161,udp,7000
6.6.6.6,60.60.60.60,77777,162,tcp,8000
headers=sc.textFile("file:///data/connections.csv").first()
filtered_rdd = sc.textFile("file:///data/connections.csv").filter(lambda x: x!=headers and x.strip())
//Tranformations -> filter , No of Stages->1
for i in filtered_rdd.map(lambda x: (x.split(",")[0], int(x.split(",")[-1]))).reduceByKey(lambda x, y:x+y).collect(): print("IP:{}, Bytes:{}".format(i[0],i[1]))
//Transformations -> map, reduceByKey Actions -> collect()
IP:6.6.6.6, Bytes:8000
IP:4.4.4.4, Bytes:6000
IP:3.3.3.3, Bytes:5000
IP:1.1.1.1, Bytes:3000
No Of Stages: 3; 1 for all Narrow Transformations (map and hadoopRDD) , 1 for wide transformation(reduceByKey) and 1 collect
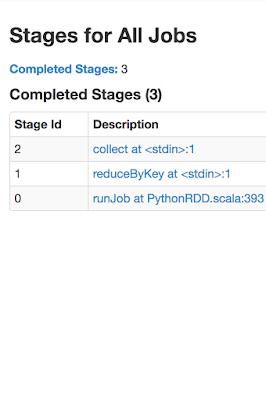
What is interesting to note is that in stage-1 and stage-2 we have shuffle read and shuffle write respectively and hence they are wide transformations and separate stages apart from stage-0.
Lets take a look at the break up of the timings of stage-1:

As seen above, the Result serialisation time is also included in the stage-1. This is the major difference with respect to our Q2 example, where serialisation Time is constituted in stage-3 due to sortBy transformation in the stage-3.
Lets take a look at the break up of the timings of stage-2:

Q2. How can you sort the results of above ?
for i in filtered_rdd.map(lambda x: (x.split(",")[0], int(x.split(",")[-1]))).reduceByKey(lambda x, y:x+y).sortBy(lambda x: x[1],ascending=False).collect(): print("IP:{}, Bytes:{}".format(i[0],i[1]))
IP:6.6.6.6, Bytes:8000
IP:5.5.5.5, Bytes:7000
IP:2.2.2.2, Bytes:7000
IP:4.4.4.4, Bytes:6000
IP:3.3.3.3, Bytes:5000
IP:1.1.1.1, Bytes:3000
//Transformations -> map, filter, reduceByKey, sortBy; Actions -> collect()
//No of Stages : 3
Also, lets take a look at the break up of the timings of stage-1:

Lets take a look at the break up of the timings of stage-2:

Q3. Find the Average Bytes sent by each srcIp?
for i in filtered_rdd.map(lambda x: (x.split(",")[0], (int(x.split(",")[-1]), 1))).reduceByKey(lambda x, y: (x[0]+y[0],x[1]+y[1])).mapValues(lambda x: x[0]/x[1]).collect(): print("IP:{}, Bytes:{}".format(i[0],i[1]))
IP:6.6.6.6, Bytes:8000
IP:4.4.4.4, Bytes:6000
IP:3.3.3.3, Bytes:5000
IP:5.5.5.5, Bytes:7000
IP:2.2.2.2, Bytes:3500
IP:1.1.1.1, Bytes:1500
//Tranformations -> filter, reduceByKey, mapValues; Actions -> collect()
//No of Stages: 3
Lets take a look at the break up of the timings of stage-0:

Lets take a look at the break up of the timings of stage-1:

Lets take a look at the break up of the timings of stage-2:

Q.4 Find the Top 1 Interaction-> ?
for i in filtered_rdd.map(lambda x: ((x.split(",")[0],x.split(",")[1]),int(x.split(",")[-1])) ).map(lambda x: (tuple(sorted(x[0])),x[1])).reduceByKey(lambda x , y : x + y).sortBy(lambda x: x[1],ascending=False).take(1): print("Top Interactions {} <-> {} : {}".format(i[0][0],i[0][1],i[1]))
//Top Interactions 6.6.6.6 <-> 60.60.60.60 : 8000
/usr/bin/pyspark
logger = sc._jvm.org.apache.log4j
logger.LogManager.getLogger("org"). setLevel( logger.Level.INFO )
file: connections.csv
srcIp,dstIp,srcPort,dstPort,protocol,bytes1.1.1.1,10.10.10.10,11111,22,tcp,1000
1.1.1.1,10.10.10.10,22222,69,udp,2000
2.2.2.2,20.20.20.20,33333,21,tcp,3000
2.2.2.2,30.30.30.30,44444,69,udp,4000
3.3.3.3,30.30.30.30,44444,22,tcp,5000
4.4.4.4,40.40.40.40,55555,25,tcp,6000
5.5.5.5,50.50.50.50,66666,161,udp,7000
6.6.6.6,60.60.60.60,77777,162,tcp,8000
Q1. Find the Sum of Bytes sent by each srcIp?
headers=sc.textFile("file:///data/connections.csv").first()
filtered_rdd = sc.textFile("file:///data/connections.csv").filter(lambda x: x!=headers and x.strip())
//Tranformations -> filter , No of Stages->1
for i in filtered_rdd.map(lambda x: (x.split(",")[0], int(x.split(",")[-1]))).reduceByKey(lambda x, y:x+y).collect(): print("IP:{}, Bytes:{}".format(i[0],i[1]))
//Transformations -> map, reduceByKey Actions -> collect()
IP:6.6.6.6, Bytes:8000
IP:4.4.4.4, Bytes:6000
IP:3.3.3.3, Bytes:5000
IP:5.5.5.5, Bytes:7000
IP:2.2.2.2, Bytes:7000IP:1.1.1.1, Bytes:3000
No Of Stages: 3; 1 for all Narrow Transformations (map and hadoopRDD) , 1 for wide transformation(reduceByKey) and 1 collect

What is interesting to note is that in stage-1 and stage-2 we have shuffle read and shuffle write respectively and hence they are wide transformations and separate stages apart from stage-0.
Lets take a look at the break up of the timings of stage-1:

As seen above, the Result serialisation time is also included in the stage-1. This is the major difference with respect to our Q2 example, where serialisation Time is constituted in stage-3 due to sortBy transformation in the stage-3.
Lets take a look at the break up of the timings of stage-2:

Q2. How can you sort the results of above ?
for i in filtered_rdd.map(lambda x: (x.split(",")[0], int(x.split(",")[-1]))).reduceByKey(lambda x, y:x+y).sortBy(lambda x: x[1],ascending=False).collect(): print("IP:{}, Bytes:{}".format(i[0],i[1]))
IP:6.6.6.6, Bytes:8000
IP:5.5.5.5, Bytes:7000
IP:2.2.2.2, Bytes:7000
IP:4.4.4.4, Bytes:6000
IP:3.3.3.3, Bytes:5000
IP:1.1.1.1, Bytes:3000
//Transformations -> map, filter, reduceByKey, sortBy; Actions -> collect()
//No of Stages : 3
Also, lets take a look at the break up of the timings of stage-1:

Lets take a look at the break up of the timings of stage-2:

Q3. Find the Average Bytes sent by each srcIp?
for i in filtered_rdd.map(lambda x: (x.split(",")[0], (int(x.split(",")[-1]), 1))).reduceByKey(lambda x, y: (x[0]+y[0],x[1]+y[1])).mapValues(lambda x: x[0]/x[1]).collect(): print("IP:{}, Bytes:{}".format(i[0],i[1]))
IP:6.6.6.6, Bytes:8000
IP:4.4.4.4, Bytes:6000
IP:3.3.3.3, Bytes:5000
IP:5.5.5.5, Bytes:7000
IP:2.2.2.2, Bytes:3500
IP:1.1.1.1, Bytes:1500
//Tranformations -> filter, reduceByKey, mapValues; Actions -> collect()
//No of Stages: 3
Lets take a look at the break up of the timings of stage-0:

Lets take a look at the break up of the timings of stage-1:

Lets take a look at the break up of the timings of stage-2:

Q.4 Find the Top 1 Interaction-> ?
for i in filtered_rdd.map(lambda x: ((x.split(",")[0],x.split(",")[1]),int(x.split(",")[-1])) ).map(lambda x: (tuple(sorted(x[0])),x[1])).reduceByKey(lambda x , y : x + y).sortBy(lambda x: x[1],ascending=False).take(1): print("Top Interactions {} <-> {} : {}".format(i[0][0],i[0][1],i[1]))
//Top Interactions 6.6.6.6 <-> 60.60.60.60 : 8000
Comments