Setup hadoop and spark on MAC
In this article, i'll take you through simple steps to setup hadoop/spark and run a spark job.
Step1: Setup the java
Step-2 Setup SSH Keyless



Step1: Setup the java
- run the command: java version & if not installed then download the one.
- After installation get the JAVA_HOME with command: /usr/libexec/java_home
- Update the .bashrc with the JAVA_HOME as: export JAVA_HOME=
Step-2 Setup SSH Keyless
- Enable remote login in System Preference=> sharing
- Generate rsa key: ssh-keygen -t rsa -P ''
- Add the RSA key to authorized key: cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Check ssh localhost ; it shouldn't prompt for the password.
Step-3: Setup hadoop- Download hadoop2.7.2.tar.gz: http://www.apache.org/dyn/closer.cgi/hadoop/common/
- Extract the tar file and move the hadoop2.7.2 to /usr/local/hadoop
- Setup the configuration files: [If the configuration files doesn't exist as they are copy from corresponding template files]
- Update /usr/local/hadoop/etc/hadoop/hdfs-site.xml
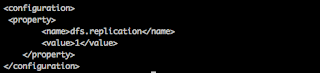

2. Update /usr/local/hadoop/etc/hadoop/core-site.xml

3. Update /usr/local/hadoop/etc/hadoop/mapred-site.xml

4. Update /usr/local/hadoop/etc/hadoop/yarn-site.xml

Step-4: Setup spark/Scala:
- Download Scala scala-2.11.8.tgz, extract it and move scala-2.11.8 to /usr/local/scala
- Download Spark without hadoop: spark-2.0.0-bin-without-hadoop.tgz , extract it and move spark-2.0.0-bin-without-hadoop to /usr/local/spark
Step-5: Setup Environment Variables:-
The most important part now is setting of the environment variables to link Java,Scala,spark and hadoop components.
1. Update .bashrc:
export JAVA_HOME=$(/usr/libexec/java_home)
export HADOOP_HOME=/usr/local/hadoop
export PATH=${PATH}:/usr/local/scala/bin
export PATH=${PATH}:/usr/local/hadoop/bin
export PATH=${PATH}:/usr/local/spark/bin
export SPARK_HOME=/usr/local/spark/
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
2. Update /usr/local/spark/conf/spark-env.sh:
export HADOOP_CONF_DIR=$HADOOP_CONF_DIR
export HADOOP_HOME=${HADOOP_HOME}
export SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=/tmp/spark-events
SPARK_DIST_CLASSPATH="$HADOOP_HOME/etc/hadoop/*:$HADOOP_HOME/share/hadoop/common/lib/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/hdfs/lib/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/yarn/lib/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/tools/lib/*"
Step-6: Start Hadoop/Yarn:
Run following commands:
/usr/local/hadoop/bin/hdfs namenode -format
/usr/local/hadoop/sbin/start-dfs.sh
/usr/local/hadoop/sbin/start-yarn.sh
Step-7: Create directory/files in hadoop & access them:
hdfs dfs -mkdir /user
$ hdfs dfs -ls /user
Found 2 items
drwxr-xr-x - indu.sharma supergroup 0 2016-09-16 19:32 /user/indu.sharma
-rw-r--r-- 1 indu.sharma supergroup 13612367 2016-09-16 21:45 /user/input.txt
Step-8: Viewing the Hadoop UI:
Open the browser and type: http://localhost:50070/

Step-9: Run the spark Job as: [Provided you have input.txt file in hdfs and wordcount.py in ur pwd]
spark-submit --master yarn --deploy-mode client --executor-memory 1G --num-executors 2 --properties-file /usr/local/spark/conf/spark-defaults.conf wordcount.py /user/input.txt 2
Step-10: Viewing your spark jobs on UI:
Open you browser and type: http://localhost:8088

Step-8: Viewing the Hadoop UI:
Open the browser and type: http://localhost:50070/

Step-9: Run the spark Job as: [Provided you have input.txt file in hdfs and wordcount.py in ur pwd]
spark-submit --master yarn --deploy-mode client --executor-memory 1G --num-executors 2 --properties-file /usr/local/spark/conf/spark-defaults.conf wordcount.py /user/input.txt 2
Step-10: Viewing your spark jobs on UI:
Open you browser and type: http://localhost:8088

Comments