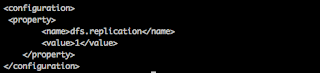
The points to remember while developing a spark application
A. The resources allocation should be optimised i.e following needs to be considered: 15 Cores/Exec can lead to HDFS I/O Throuput is Bad; so best core per executor is 4 to 6 Max(385MB,0.07*ExecMemory) is required for direct memory i.e Overhead. Don’t have too high executor memory ; Garbage collections & parallelism would be impacted. Consider at least 1 core & 1GB for the Os/hadoop Consider the resources for one Application Master B. The no of partitions should be optimised i.e initial partitions and intermediate partitions No of Initial partitions = No of blocks in hadoop or same as value of spark.default.parallelism Size of each SufflePartitions shouldn’t be more than 2G, otherwise job fails with IllegalArgument MAX_VALUE. No of child partitions >=< No of partitions in parent RDD. C. Always use reduceByKey instead of groupByKey and treeReduce instead of reduce wherever possible. D. Tak...